CUDAを使ったプログラミング データ検索
ここ2,3年、Pythonを使って間接的にCUDAを利用することがあったのですが、実際にCUDAを使ったプログラミングがどういうものか興味があったので、Visual C++とCUDAを使ってデータを検索するプログラムを作成してみました
CUDAの導入とソースはこちらのサイトを参考にしました。
環境はwindows10, Visual Studio 2022 Community, CUDA 12.0です。
意外と簡単
ハードウェアの操作をするので、どんな難しいプログラムが待っているのだろうと身構えていましたが、拍子抜けするほど簡単でした。
大雑把に説明すると、GPUのメモリにデータをコピーして、共通の関数(カーネル)を呼び出すだけです。(本当に大雑把)
データ1つにつき1つのスレッドが生成されて、共通の関数が呼び出されるという仕組みになっています。
どの位置を処理するかは、決まった計算式があります。同時並列的に処理が行われるため、順序良く処理をするといったことが出来ません。
プログラムの難しさというよりは、どんな使い方をするかという部分が悩むところです。
GPUは膨大な処理を行うのに向いているということなので、プロセスメモリの検索の高速化に使えるんじゃないかと考え、CUDAを使ったバイナリ検索のプログラムに挑戦してみました。
一応、結果だけ言うと失敗でした(ハイ
とりあえず動かす
とりあえずシンプルな検索用カーネルを作成しました
引数1には0~1024までの連番が入ったvalues、引数2には結果を返すresultsが入っています
5の倍数だった場合、その数値を返すという処理にしました
#include <stdio.h>
#include <iostream>
#include <time.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "cuda01.cuh"
// GPUを使った検索(カーネル)
__global__ void gpu_search(int* values, int* results)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x; // インデックスを計算
if (values[idx] % 5 == 0)
results[idx] = values[idx];
}
// CPUを使った検索
void cpu_search(int n, int* values, int* results)
{
for (int i = 0; i < n; i++) {
if (values[i] % 5 == 0) {
results[i] = values[i];
}
}
}
// メイン処理(外部cppから呼び出す)
int cuda_call(void)
{
int N = 256 * 4; //256の倍数にしないと正常に動作しない
int* host_values, * host_results, * dev_values, * dev_results;
// CPU側の領域確保
host_values = (int*)malloc(N * sizeof(int));
host_results = (int*)malloc(N * sizeof(int));
// 連番生成
for (int i = 0; i < N; i++) {
host_values[i] = i;
}
memset(host_results, 0, N * sizeof(int)); // 戻り値配列を0初期化
// CPUで計算
int start_cpu = clock(); // CPUタイマー
cpu_search(N, host_values, host_results);
int ms_cpu = clock() - start_cpu;
// GPUで計算
int start_gpu = clock(); // GPUタイマー
// デバイス(GPU)側の領域確保
cudaMalloc(&dev_values, N * sizeof(int));
cudaMalloc(&dev_results, N * sizeof(int));
// CPU ⇒ GPUのデータコピー
cudaMemcpy(dev_values, host_values, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_results, host_results, N * sizeof(int), cudaMemcpyHostToDevice);
// GPUで計算
gpu_search <<< (N + 255) / 256, 256 >>> (dev_values, dev_results);
// GPU ⇒ CPUのデータコピー
cudaMemcpy(host_results, dev_results, N * sizeof(int), cudaMemcpyDeviceToHost);
int ms_gpu = clock() - start_cpu;
// 戻り値を出力
std::cout << "result:" << std::endl;
for (int j = 0; j < N; j++) {
std::cout << host_results[j] << ",";
}
std::cout << std::endl;
// 計測時間を出力
std::cout << "CPU: " << ms_cpu << "[ms]" << ", GPU: " << ms_gpu << "[ms]" << std::endl;
return 0;
}
実行結果は
図1
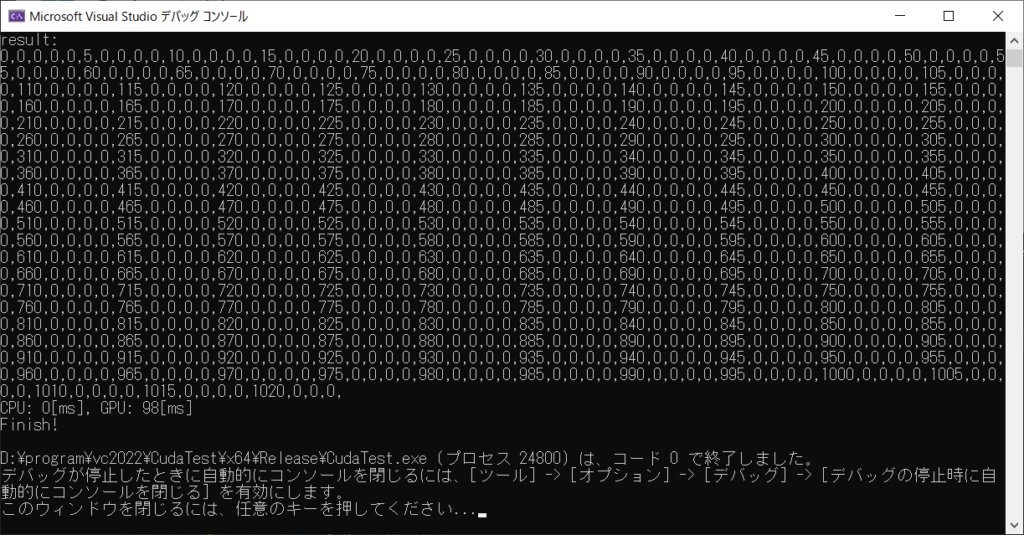
ちゃんと5の倍数だけが出力されていますね
処理時間を見ると、CPUが0msなのに対し、GPUが98msと大きく遅れています。メモリを確保したりデータをコピーしたりするオーバーヘッド部分があるせいでしょうか
ちなみにCPUはi5 13600KF, GPUはRTX3070です
データ量を増やしたらどうなるか見てみましょう。
int[256] * 4000(4MB)

256 * 40000(40MB)

256 * 400000(400MB)

256 * 4000000(4GB)

256 * 4000000(4GB): 13600KFを3500MHzにダウンクロック

これ以上はRTX3070のメモリ容量8GBを超えてしまうので増やせません。
処理速度は、CPUが約10倍ずつ線形的に増加しているのに対し、GPUは抑えが効いています。しかし、それでもGPUがCPUの速度に追いつくということはありませんでした。
CPUクロックを下げるとGPUの速度も落ちていることから、データコピーの部分で時間を取られているのだと思います。
そして、更に大きな問題に直面します。検索結果を前詰めで出力したいと考えたときに、同期の問題で出力先のインデックスを計算することが出来ません。例えば、戻り値配列を前から順に検索して0ならば書き換える、0でなければインデックスを増加して書き換えるという処理を書いたとします。それぞれのスレッドが前から順に早いもの勝ちで結果を書き込みそうなものですが、ほぼすべてのスレッドが”0ならば”の位置を同時に実行してしまい、同じインデックスに結果を出力してしまいます。
__global__ void gpu_search(int* values, int* results)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x; // インデックスを計算
int ofs = 0;
if (values[idx] % 5 == 0) {
while (true) {
if (results[ofs] == 0) {
results[ofs] = values[idx];
break;
}
else {
ofs++;
if (ofs >= 1024)
break;
}
__syncthreads();
}
}
}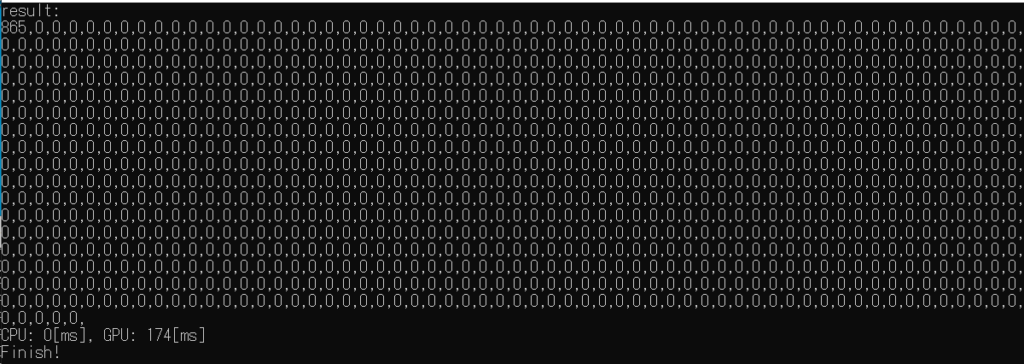
すべてのスレッドが0番目に出力しています
順番に出力させる
ここで結果を順番に出力させるために一工夫加えます。
処理可能フラグ配列flagsを用意して、処理が終わったら次のスレッドの処理可能フラグを立てるという方法です。
flags[0]に1を入れてからカーネルを呼び出します。
// GPUを使った検索(カーネル)
__global__ void gpu_search(int* values, int* results, int* flags)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x; // インデックスを計算
int ofs = 0;
while (flags[idx] != 1) {
__syncthreads();
}
if (values[idx] % 5 == 0) {
while (true) {
if (results[ofs] == 0) {
results[ofs] = values[idx];
break;
}
else {
ofs++;
if (ofs >= 1024)
break;
}
}
}
flags[idx + 1] = 1;
}注意点として、__syncthreads()を呼び出さないとプログラムが固まります。
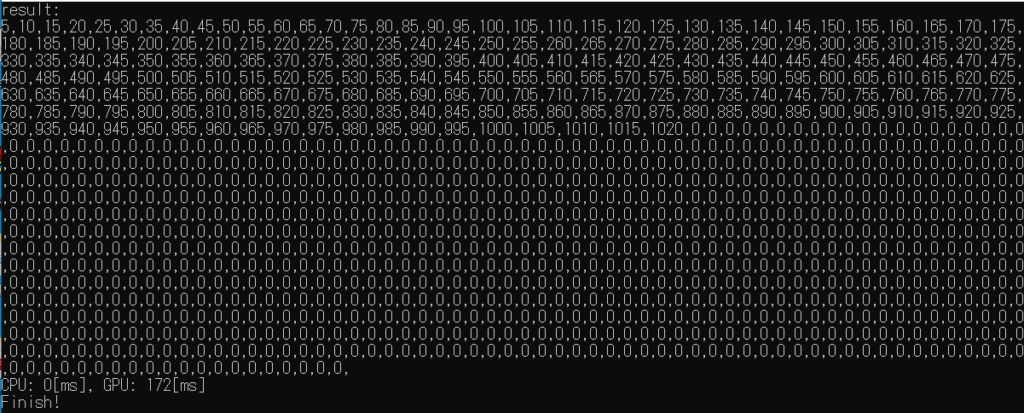
ちゃんと前詰めで表示されました。共通の出力位置用の変数などを用いれば出力位置を検索する必要も無さそうです。
しかし、この方法だと処理が並列に実行されないため、ますます実行速度が遅くなってしまいます。
試しにデータ量を増やして実行すると
256*4000(4MB)

4MBで20秒、これでは使い物になりませんね。
そもそも、この方法では1つのスレッドで全部のデータを処理しているのと変わりません。
1つのスレッドに複数の処理を行わせる
そこで、1つのスレッドに複数の範囲を検索をさせてみてはどうだろうと考えました。
0~255番地をスレッド1で検索、256~512番地をスレッド2で検索、といった感じです。
検索部分を同時並行的に行い、結果出力処理部分だけをフラグを用いて順番に連結するという方法です。
#define BUF_SIZE (4000)
#define BATCH_SIZE (256)
// GPUを使った検索(カーネル)
__global__ void gpu_search(int* values, int* results, int* flags, int *pos)
{
int idx = blockIdx.x * blockDim.x + threadIdx.x; // インデックスを計算
int ofs = 0;
int i = 0;
if (idx % BATCH_SIZE != 0)
return;
for (i = 0; i < BATCH_SIZE; i++) {
if (values[idx + i] % 5 == 0) {
results[idx + ofs] = values[idx + i];
ofs++;
}
}
if (idx == 0) {
pos[0] = ofs;
flags[idx + BATCH_SIZE] = 1;
return;
}
while (flags[idx] != 1) {
__syncthreads();
}
for (i = 0; i < BATCH_SIZE; i++) {
if (results[idx + i] != 0) {
results[pos[0]] = results[idx + i];
pos[0]++;
}
else {
break;
}
}
flags[idx + BATCH_SIZE] = 1;
}idが256(処理サイズ)の倍数でないスレッドは即終了させます。
1つのスレッドが256個のデータをチェックし、それぞれのidの先頭位置から前詰めに検索結果を埋めていきます。
そこまで終わったらスレッドの同期を取り、検索結果を順番に連結します。
スレッド番号0は、コピー元とコピー先のアドレスが同じになってエラーを出すため、出力位置(pos)だけをシークして終了させます。
データサイズと処理サイズを変更しながら、速度を比較してみました。
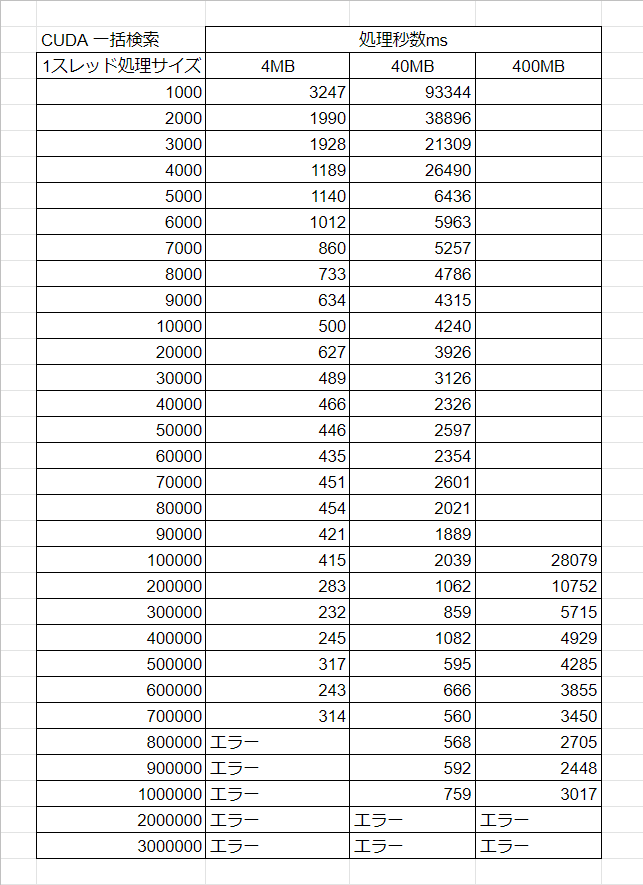
このような結果になりました。
1つのスレッドで処理するデータ量が増えるほど速くなっています。やはりデータ連結部分がネックになっているということですね。
ならば1つのスレッドに全部やらせたら一番速いって事になりそうですが、1つのスレッドで1000000個(4MB)を超えてアクセスしようとするとエラーが出ます。1つのスレッドに任せられるのは最大900000個程度までですね。
先ほどの結果と比べてみると、4MBで20秒だったものが400MBで2.5秒と、かなり高速化を図れたのではないかと思います。
それでもCPUだけで検索したほうが断然速いですがorz
ちなみに2GBを処理させたら30秒でした。データ連結部分をコメントアウトして実行してみると1.2秒。連結部分だけをCPUにさせると良さそうです。
400MB分の検索済みデータをCPUで連結すると 54ms→7msと短縮を図れましたが、GPU処理が400ms掛かってます
結果は×
CUDAを用いてプロセスメモリのサーチを高速化できないかと考えての挑戦でしたが、見事に失敗しました。
検索結果の出力が順次的であり、データ比較がデータコピーよりも速く行えるという性質上、単純な検索ではどう足搔いてもCPUが勝ってしまいます
CUDAは行列演算のように、出力先が決まっていて、ある程度複雑な計算を行うようなものでないとパフォーマンスを発揮できないようですね
せっかくCUDAの使い方を覚えたので、何か面白い使い方ができないか模索してみたいと思いますノシ
1件の返信
[…] 前回は、データ検索プログラムにCUDAを使おうとして失敗しました […]